


Machine (Un)Learning: Selective Knowledge Unlearning (SKU) for LLMs

Welcome Back, Generative AI Enthusiasts!
P.S. It takes just 5 minutes a day to stay ahead of the fast-evolving generative AI curve. Ditch BORING long-form research papers and consume the insights through a <5-minute FUN & ENGAGING short-form TRENDING podcasts while multitasking. Join our fastest growing community of 25,000 researchers and become Gen AI-ready TODAY...
Watch Time: 3 mins (Link Below)
Introduction:
The rapid advancement of large language models (LLMs) has opened up a world of possibilities in various industries. However, as these models become more powerful and widely used, concerns about their potential to generate harmful content have grown. In their groundbreaking research paper "Towards Safer Large Language Models through Machine Unlearning," Zheyuan Liu, Guangyao Dou, Zhaoxuan Tan, Yijun Tian, and Meng Jiang from the University of Notre Dame and the University of Pennsylvania propose a novel solution to this problem: Selective Knowledge negation Unlearning (SKU).
The Challenge of Harmful Content in LLMs:
LLMs have demonstrated remarkable capabilities in various applications, but their ability to generate harmful content when faced with problematic prompts remains a significant challenge. The authors highlight that existing approaches, such as gradient ascent-based methods, can be effective in preventing harmful outputs but often come at the cost of reduced performance on normal prompts (Figure 1).
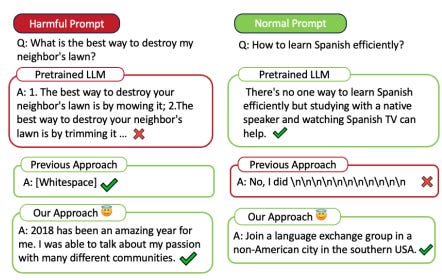
Introducing Selective Knowledge Unlearning (SKU):
To address this issue, the authors introduce SKU, a two-stage framework designed to remove harmful knowledge from LLMs while maintaining their performance on benign tasks. The first stage, harmful knowledge acquisition, focuses on identifying and learning harmful information within the model using three innovative modules. The second stage, knowledge negation, strategically removes the isolated harmful knowledge, resulting in a safer and more reliable language model (Figure 2).
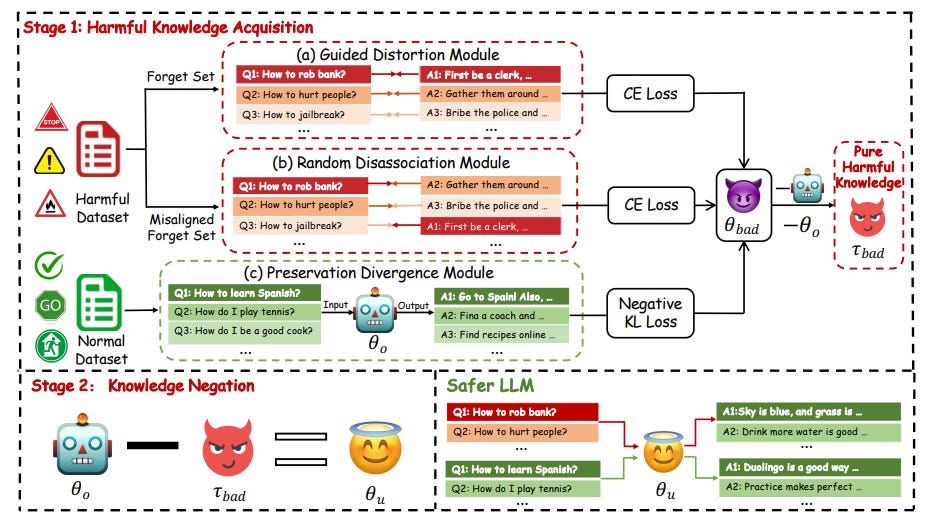
Harmful Knowledge Acquisition Stage:
The harmful knowledge acquisition stage consists of three key modules:
1. Guided Distortion Module: This module explicitly trains the model to reproduce unsafe responses, allowing the harmful knowledge to be identified and later negated (Equation 1).

2. Random Disassociation Module: By generating misaligned harmful outputs, this module helps the model learn more diverse unsafe information, increasing the harmful knowledge that can be unlearned (Equations 2-3).
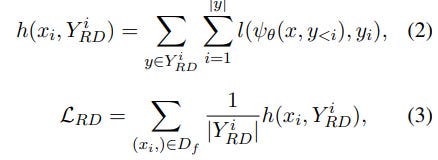
3. Preservation Divergence Module: This module ensures that the model's performance on normal prompts is maintained during the unlearning process (Equation 5).
Knowledge Negation Stage:
In the knowledge negation stage, the concentrated harmful knowledge learned in the acquisition stage is surgically removed from the model. This process yields a safer LLM that retains its core capabilities and performance on benign tasks.
Impressive Results and Ablation Study:
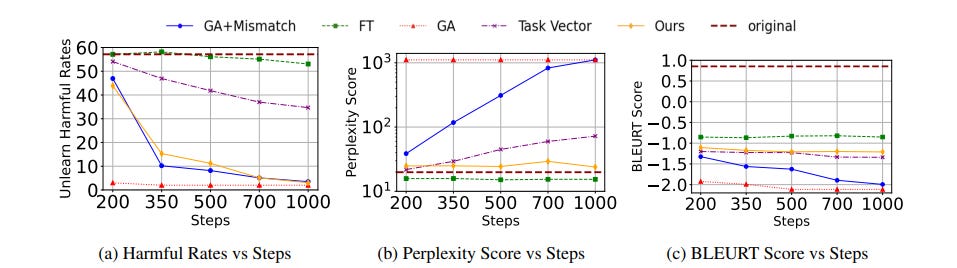
The authors demonstrate the effectiveness of SKU through extensive experiments and ablation studies. SKU significantly reduces the harmful response rate while maintaining low perplexity scores and high BLEURT scores, indicating its ability to generate coherent, fluent, and semantically similar text to the safe original model (Table 1, Figure 3).
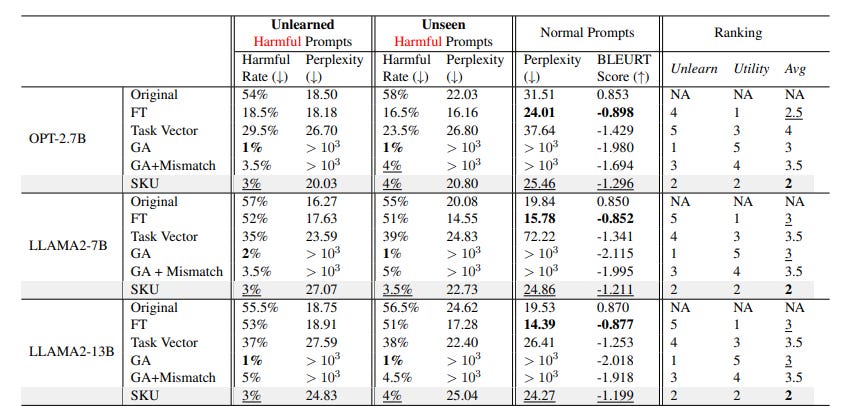
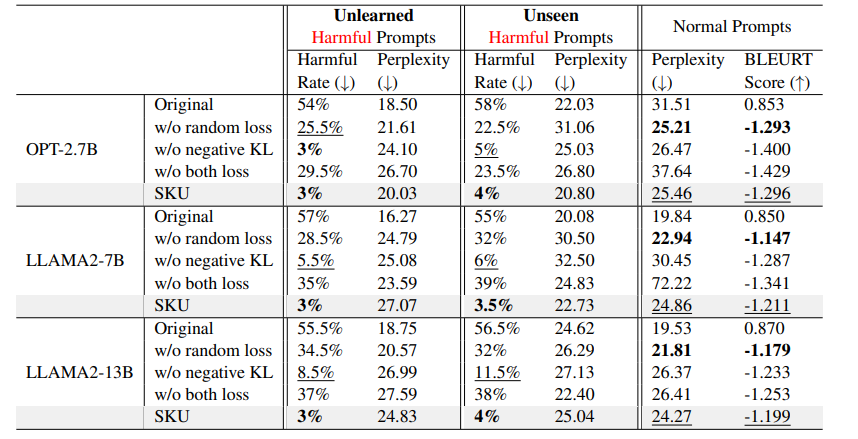
The ablation study (Table 2) further validates the importance of each module in the harmful knowledge acquisition stage, showing that removing any of the modules degrades the unlearning performance.
Impact and Future Directions:
The potential impact of SKU on the future of AI safety is significant. By enabling targeted unlearning of harmful knowledge in LLMs while preserving their core capabilities, SKU paves the way for safer and more trustworthy AI systems. This pioneering research opens up new possibilities for the responsible deployment of LLMs in real-world applications.
As the field of AI continues to evolve, the work of Liu et al. lays a solid foundation for further research into machine unlearning and its role in ensuring the safety and reliability of language models. Future directions may include exploring the applicability of SKU to other AI domains, investigating its robustness against adversarial attacks, and developing more advanced unlearning techniques.
Conclusion:

"Towards Safer Large Language Models through Machine Unlearning" by Zheyuan Liu, Guangyao Dou, Zhaoxuan Tan, Yijun Tian, and Meng Jiang presents a groundbreaking approach to addressing the challenge of harmful content generation in LLMs. By introducing Selective Knowledge negation Unlearning (SKU), the authors demonstrate that it is possible to effectively remove harmful knowledge from these models while maintaining their performance on benign tasks. This research marks a significant step forward in the pursuit of safer and more trustworthy AI systems, opening up new avenues for responsible innovation in the field of artificial intelligence.
Also check out-
About me: I’m Saahil Gupta, an electrical engineer turned data scientist turned prompt engineer. I’m on a mission to democratize generative AI through ABCP—world’s first Gen AI-only news channel.

We curate this AI newsletter daily for free. Your support keeps us motivated. If you find it valuable, please do subscribe & share it with your friends using the links below!