


Goodbye, Chain of Thought. Hello, Buffer of Thoughts..

Welcome Back, Generative AI Enthusiasts!
P.S. It takes just 5 minutes a day to stay ahead of the fast-evolving generative AI curve. Ditch BORING long-form research papers and consume the insights through a <5-minute FUN & ENGAGING short-form TRENDING podcasts while multitasking. Join our fastest growing community of 25,000 researchers and become Gen AI-ready TODAY...
Watch Time: 3 mins (Link Below)
Introduction:
In the rapidly evolving field of Gen AI, large language models (LLMs) have demonstrated remarkable capabilities in various reasoning tasks. However, traditional approaches to enhancing LLM reasoning, such as Chain of Thought prompting, often face limitations in efficiency and generalization. A groundbreaking research paper, "Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models" by Ling Yang, Zhaochen Yu, Tianjun Zhang, Shiyi Cao, Minkai Xu, Wentao Zhang, Joseph E. Gonzalez, and Bin Cui, introduces a novel technique called Buffer of Thoughts (BoT) that revolutionizes language model reasoning by enabling LLMs to learn from their own problem-solving experiences.
The Limitations of Traditional Approaches:
Before diving into the Buffer of Thoughts method, it's essential to understand the limitations of traditional approaches to language model reasoning. Single-query methods, such as Chain of Thought prompting, rely on manually designed prompts for each task, lacking universality and generalization (Figure 1). Multi-query methods, like Tree of Thoughts and Graph of Thoughts, explore multiple reasoning paths but are computationally intensive and fail to leverage insights from previously solved problems (Figure 1). These limitations highlight the need for a more efficient and adaptable approach to LLM reasoning.
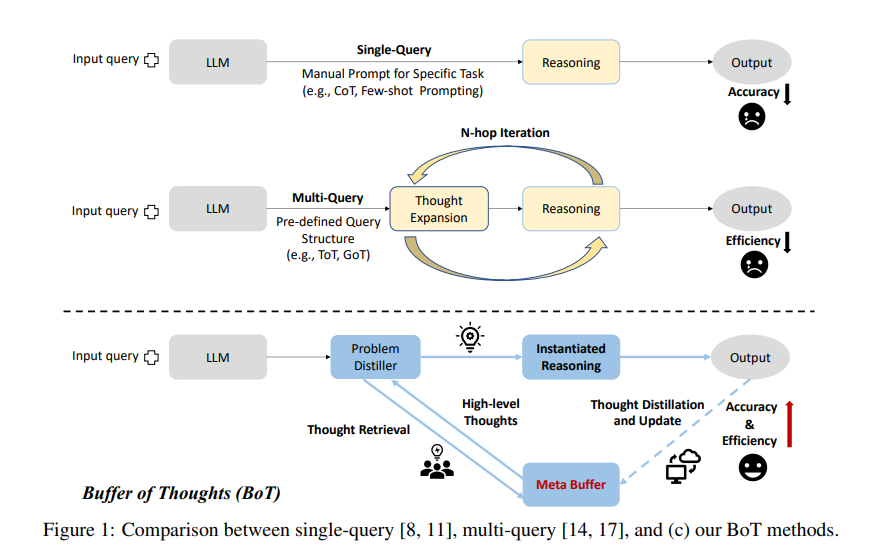
Introducing Buffer of Thoughts:
Buffer of Thoughts addresses these limitations by enabling LLMs to accumulate and reuse problem-solving knowledge across tasks. The core idea is to maintain a meta-buffer of reusable "thought templates" that capture high-level reasoning approaches. These templates are distilled from the LLM's own problem-solving experiences and can be retrieved and instantiated with problem-specific details to enable more accurate and efficient reasoning on new tasks (Figure 2).
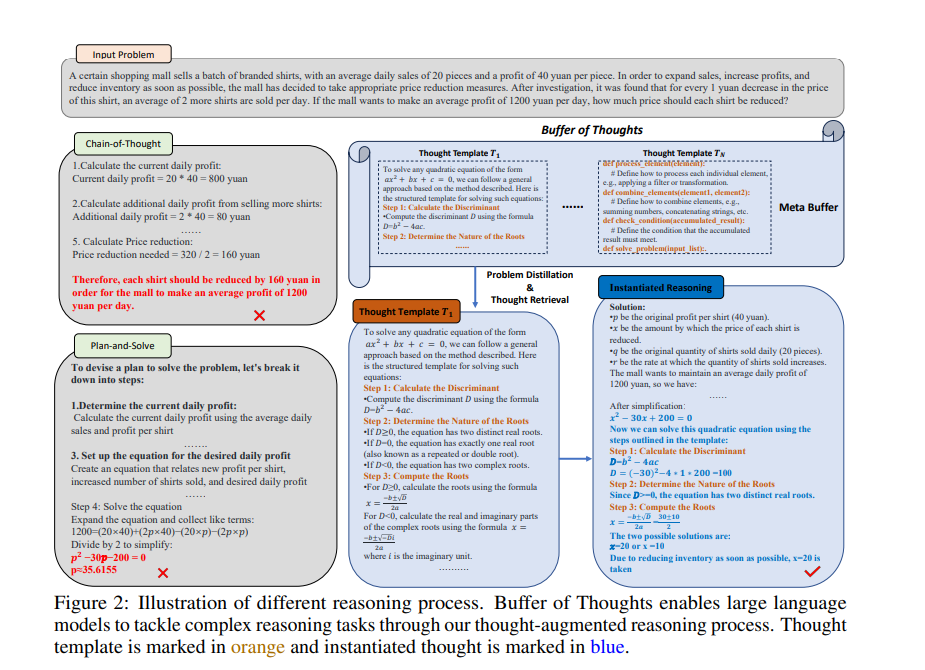
The BoT Reasoning Process:
The Buffer of Thoughts reasoning process consists of four key steps (Figure 2):
Problem Distillation: The input problem is analyzed to extract key information and constraints.
Thought Retrieval: A relevant thought template is retrieved from the meta-buffer based on the distilled problem information.
Instantiated Reasoning: The retrieved template is instantiated with problem-specific details, and the LLM conducts the reasoning process.
Thought Distillation and Update: The overall problem-solving process is summarized, and new thought templates are distilled and added to the meta-buffer for future use.
This iterative process allows the LLM to continuously expand its meta-buffer and improve its reasoning capabilities over time.
Impressive Results:
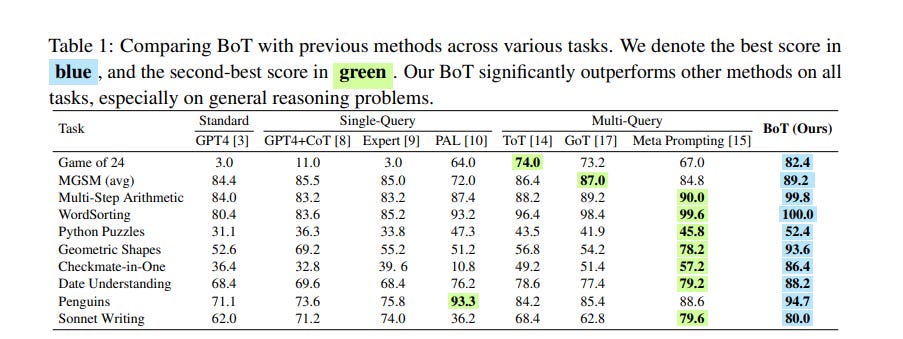
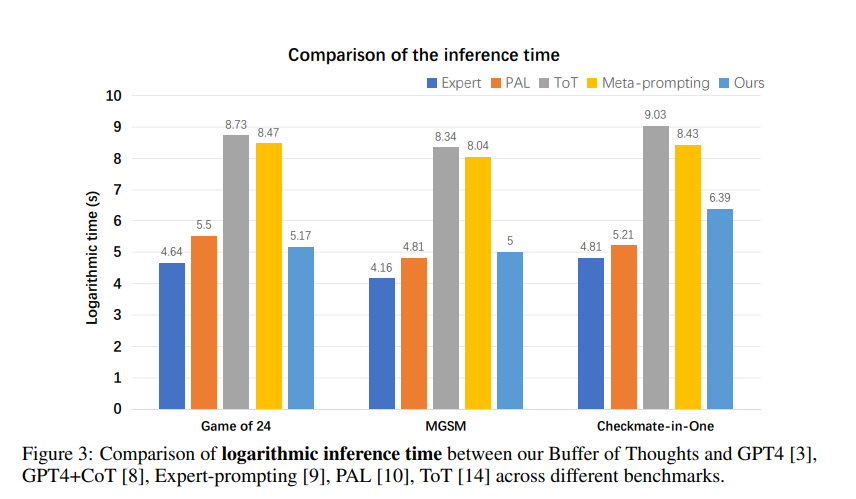
The effectiveness of Buffer of Thoughts is demonstrated through extensive experiments on a diverse set of challenging reasoning tasks. As shown in Table 1, BoT significantly outperforms previous state-of-the-art methods, achieving 11% improvement on Game of 24, 20% on Geometric Shapes, and 51% on Checkmate-in-One. Remarkably, BoT accomplishes this while requiring only 12% of the computational cost of multi-query reasoning methods on average (Figure 3).
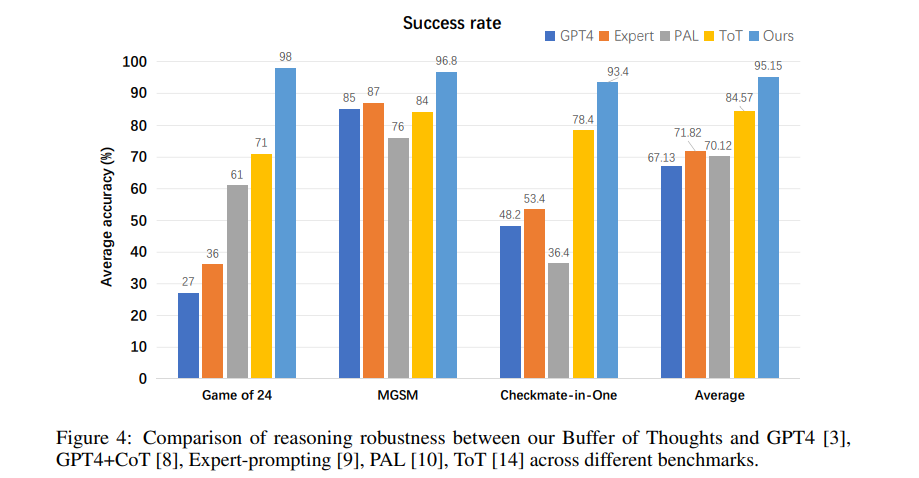
Beyond Accuracy and Efficiency: Buffer of Thoughts not only enhances reasoning accuracy and efficiency but also improves the robustness and generalization of LLMs. By learning from its own experiences and accumulating a meta-buffer of thought templates, BoT enables LLMs to tackle novel problems more effectively. As illustrated in Figure 4, BoT maintains a consistently high success rate across various tasks, surpassing other methods by 10% on average.
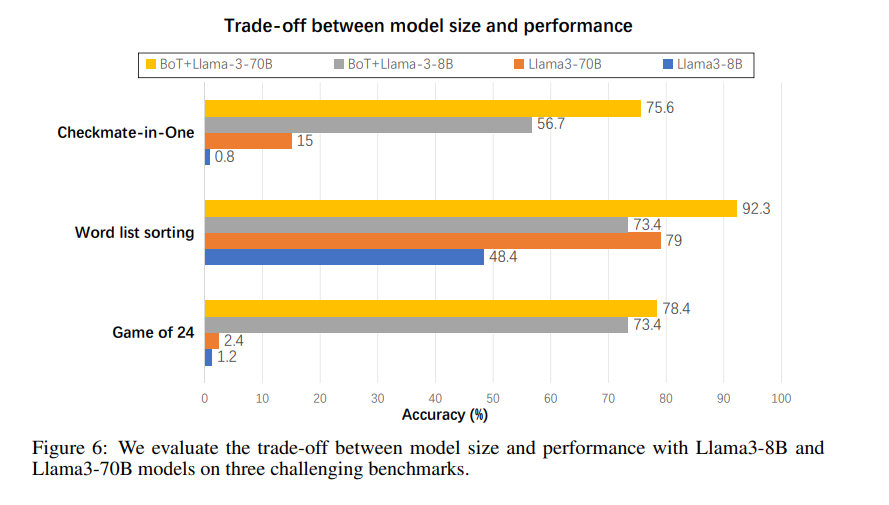
Moreover, the power of BoT is evident in its ability to elevate the reasoning capabilities of smaller LLMs. Figure 6 shows that a smaller model, such as Llama3-8B, when equipped with BoT, can rival the performance of a much larger model like Llama3-70B. This demonstrates the potential of BoT to democratize advanced reasoning capabilities and make them more accessible.
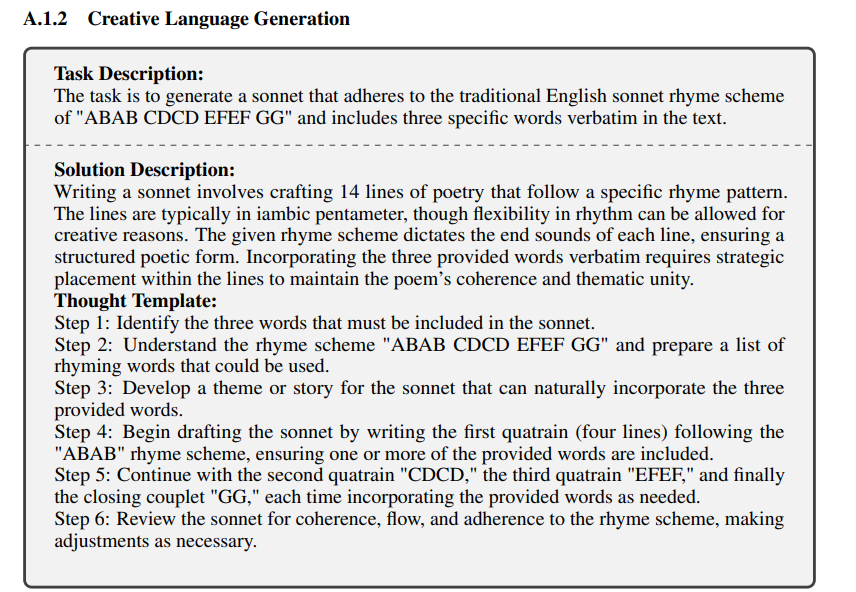
The Future of Language Model Reasoning:
The Buffer of Thoughts method represents a significant leap forward in language model reasoning. By enabling LLMs to learn from their own experiences and build up reusable problem-solving knowledge, BoT paves the way for more efficient, accurate, and robust reasoning across a wide range of tasks.
As the field of AI continues to advance, the insights from the Buffer of Thoughts research paper will undoubtedly shape the future of language model reasoning. The ability to accumulate and leverage problem-solving knowledge across tasks opens up exciting possibilities for LLMs to tackle increasingly complex and diverse challenges.




Conclusion:
The "Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models" research paper introduces a revolutionary approach to language model reasoning that addresses the limitations of traditional methods. By enabling LLMs to learn from their own experiences and build up a meta-buffer of reusable thought templates, Buffer of Thoughts achieves significant improvements in reasoning accuracy, efficiency, and robustness.
As we look towards the future of AI, the Buffer of Thoughts method represents a significant milestone in the journey towards more capable and adaptable language models. By empowering LLMs to learn and reason like humans, BoT brings us one step closer to realizing the full potential of artificial intelligence in solving complex real-world problems.
Also check out-
About me: I’m Saahil Gupta, an electrical engineer turned data scientist turned prompt engineer. I’m on a mission to democratize generative AI through ABCP—world’s first Gen AI-only news channel.

We curate this AI newsletter daily for free. Your support keeps us motivated. If you find it valuable, please do subscribe & share it with your friends using the links below!